Как EXO Labs запустили Llama на 26-летнем ПК с Pentium II
Специалисты EXO Labs успешно запустили языковую модель Llama на старом ПК, демонстрируя возможности ИИ даже на ограниченных ресурсах.
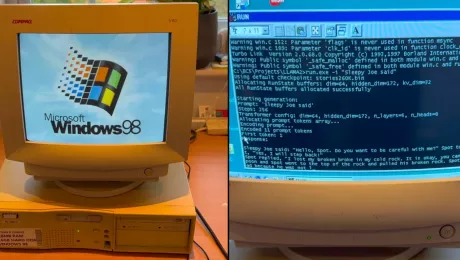
29 декабря команда EXO Labs, выступающая за доступность технологий на основе искусственного интеллекта, поделилась в своём блоге впечатляющим достижением: им удалось запустить большую языковую модель Llama на 26-летнем компьютере с Windows 98 и процессором Pentium II (с тактовой частотой 350 МГц). Для этого разработчики использовали кастомный движок Llama2.c, созданный Андреем Карпати, бывшим директором по ИИ в Tesla и одним из основателей OpenAI, который он выложил в открытый доступ на GitHub.
Запустив LLM на столь старом компьютере, специалисты поставили перед системой задачу — сгенерировать историю о Sleepy Joe («Сонный Джо»). Радует, что ИИ не только справился с этой задачей, но и создавал текст с довольно высокой скоростью. Этот опыт демонстрирует, что запуск больших языковых моделей возможен даже на устройствах с ограниченными ресурсами. Тем не менее, пользователю необходимо обладать определёнными техническими навыками, так как передача данных на такое старое устройство оказалась непростой задачей.

В блоге EXO Labs также упоминается, что скомпилировать современный код для Windows 98 было непросто. Команда смогла адаптировать движок Llama2.c с помощью устаревшей IDE и компилятора Borland C++ 5.02, внесев несколько небольших правок. Результатом стал исполняемый файл, совместимый с Windows 98. Примечательно, что полученное решение обеспечивало хорошую производительность — скорость генерации текстового контента составила 35,9 токенов в секунду при использовании модели размером 260К.

Несмотря на это, в современных условиях данная большая языковая модель может показаться довольно скромной. В то же время, способность запускать ИИ технологии на компьютере с 128 МБ оперативной памяти впечатляет. На этой системе удалось запустить и более крупные LLM, такие как Llama 3.2 1B. Однако обработка этой модели оказалась затруднена: скорость генерации снизилась до 0,0093 токена в секунду.
-
 Инновационное развитие искусственного интеллекта привлекает инвестицииКриптовалюты
Инновационное развитие искусственного интеллекта привлекает инвестицииКриптовалюты -
Как Яндекс помогает запускать большие языковые модели на обычных устройствахТехнологии
-
Coinbase покупает команду из Utopia Labs для развития платежей на базе блокчейнаКриптовалюты
-
OpenAI Привлекает 6,6 Миллиарда Долларов Достигая Оценки 157 МиллиардовКриптовалюты
-
Как KAZ-LLM помогает Казахстану в области генеративного искусственного интеллекта?Технологии
-
Мем-коин Floki поддерживает запуск IИ-агентов на BNB Chain с проектом BADКриптовалюты





