Google представила мощные ИИ-модели Gemini 2.0 с новыми функциями
Google анонсировала Gemini 2.0 Pro Experimental и Flash Thinking, подчеркивая их выдающиеся возможности и сниженные затраты на обучение нейросетей.

Корпорация Google анонсировала новую, флагманскую модель ИИ Gemini 2.0 Pro Experimental, а также революционную нейросеть Gemini 2.0 Flash Thinking, теперь доступную в приложении Gemini.[media=https://x.com/Google/status/1887170927751729385?ref_src=twsrc%5Etfw]
Модель Gemini 2.0 Pro Experimental является преемником предыдущей версии 1.5 Pro и доступна на платформах Vertex AI, Google AI Studio, а также подписчикам Advanced в приложении Gemini. Художники и исследователи подчеркивают ее навыки в программировании и способности обрабатывать сложные запросы, она "лучше воспринимает и обдумывает информацию о мире".
Контекстное окно профессиональной версии составляет 2 миллиона токенов, что позволяет ей одновременно обрабатывать информацию из всех семи книг о Гарри Поттере, оставляя в запасе порядка 400,000 слов.
Кроме того, модель Gemini 2.0 Flash теперь имеет улучшенную и экономичную версию Lite, что делает использование нейросетей еще более доступным.
Тестирование показало, что производительность серии Gemini 2.0 значительно повысилась по сравнению с предыдущей версией 1.5 по ряду параметров.
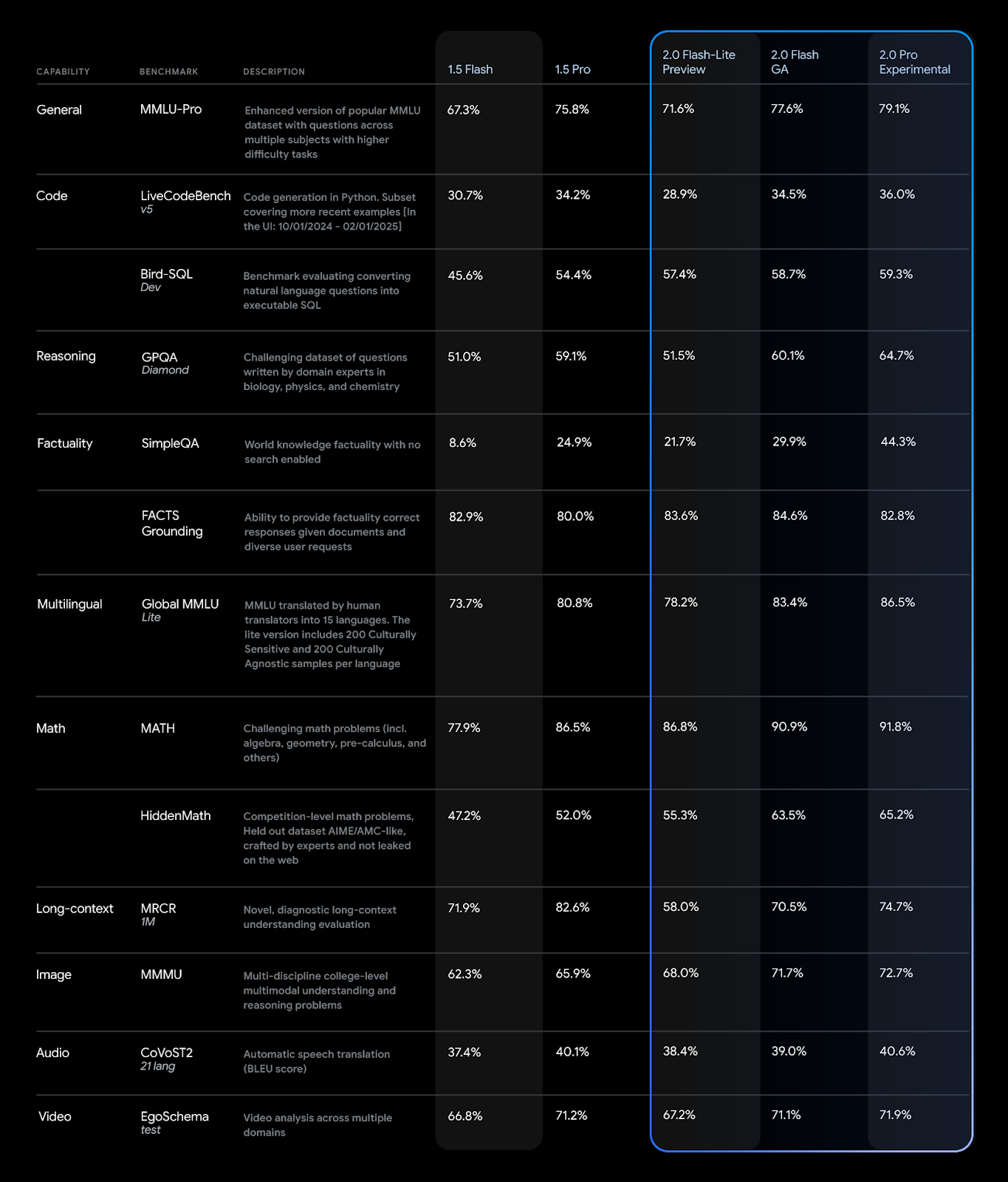
Компания также уменьшила стоимость использования Flash и Flash-Lite, опустив ее ниже значений предыдущей версии Gemini 1.5 Flash, улучшив при этом производительность систем.

Недавний шум вокруг эффективной и бюджетной китайской модели ИИ DeepSeek-R1 заставляет задуматься о целесообразности многомиллиардных инвестиций в искусственный интеллект. Укрепляется конкуренция за удешевление нейросетей.
Доступная нейросеть за $50
В январе NovaSky представила ИИ-модель с открытым исходным кодом Sky-T1, обучение которой обошлось в $450.
Исследователи из Стэнфорда и Университета Вашингтона также сделали успехи, создав рассуждающую нейросеть за менее чем $50. Модель s1 показывает результаты, аналогичные o1 от OpenAI и R1 от DeepSeek, и доступна на GitHub вместе с данными и кодом для обучения.
Команда проекта использовала готовую базовую нейросеть и доработала ее с помощью дистилляции — метода, при котором способности к рассуждению извлекаются из другой ИИ-модели, обучая на ответах.
Основой для s1 стала небольшая бесплатная ИИ-модель Qwen от Alibaba. Исследователи создали уникальный набор данных из 1000 вопросов и ответов на них с использованием данных Gemini 2.0 Flash Thinking Experimental.
Обучение проводилось на 16 графических процессорах Nvidia H100 и заняло менее 30 минут.
Дистилляция: этичный процесс?
Идея создания передовых ИИ-моделей с минимальными финансовыми затратами выглядит многообещающе. Тем не менее, крупные исследовательские лаборатории могут быть недовольны подобным подходом.
OpenAI обвинила DeepSeek в использовании данных из своего API для дистилляции без разрешения.
Разработчики s1 искали наилучший и простейший метод для достижения выдающихся результатов. Обучение прошло в рамках подхода Supervised Fine-Tuning (SFT), в котором моделям дают инструкции подражать определенному поведению в предоставленных данных.
SFT является более доступным методом по сравнению с крупномасштабным обучением с подкреплением.
Google предоставляет бесплатный доступ к Gemini 2.0 Flash Thinking Experimental через платформу Google AI Studio.
Необходимость крупных инвестиций
Несмотря на растущий интерес к дешевым нейросетям, такие гиганты, как Meta, Google и Microsoft, не планируют сокращать объемы инвестиций в обучение новых моделей.
Хотя метод дистилляции показывает свою эффективность для доработки моделей, он не дает возможности создать новые нейросети, которые могли бы значительно превзойти существующие решения.
К слову, 21 января Дональд Трамп объявил о частных инвестициях в инфраструктуру искусственного интеллекта на сумму $500 миллиардов.
-
 Gemini от Google: Чат-бот с памятью, который учитывает ваши предпочтенияКриптовалюты
Gemini от Google: Чат-бот с памятью, который учитывает ваши предпочтенияКриптовалюты -
Google представила мощную модель ИИ Gemini 2.0 с новыми функциямиКриптовалюты
-
Биржа Gemini выбирает Мальту как центр для исполнения норм MiCAКриптовалюты
-
Alibaba представляет Qwen 2.5: новый лидер в области ИИКриптовалюты
-
Google презентовал Imagen 3 - ИИ генератор изображенийТехнологии
-
OpenAI в скором времени представит новую ИИ-модель o3-miniКриптовалюты